Pesquisando sobre diferenças entre o git merge e o git rebase, achei esse post muito interessante do Blog do Grasselli.
Abaixo transcrevo parte dele:
Pull e Push
Bom, vou começar pelo mais básico, enviar e receber commits do repositório remoto.
Geralmente o pessoal acredita que a fórmula é essa:
- commito alguma coisa
- faço pull para ver se tem alguma coisa no remoto
- faço push para enviar para ele
Isso até que funciona, mas eu prefiro uma outra abordagem que deixa a árvore dos commits mais organizada.
O pull nada mais é do que um fetch (baixa objetos e referências do remoto) mais merge (junta duas ou mais histórias).
Imagine que você baixou tudo que estava no remoto e fez um commit. Enquanto você trabalhava outra pessoa enviou alguma coisa para o remoto que você não tem. Se você fizer um pull, a árvore dos commits ficará assim:
Para não ter que criar um repositório remoto para o exemplo, eu fiz o merge entre dois repositórios locais, mas o resultado é o mesmo.
Com o merge ele mostra que os commits foram feitos em paralelo, mas as vezes essa informação não é tão relevante, e vale mais a pena deixar a árvore organizada. Por isso quando eu vou fazer isso, ao invés de eu dar um pull pro remoto, eu faço um rebase. Por exemplo:
git fetch
git rebase origin/master
Ou, mais fácil de usar
git pull --rebase origin master
Com o rebase o git faz um stash de seus commits que ainda não existem no remoto, baixa os branchs do remoto e recoloca seus commits após o que veio dele. Ficaria assim:

Viram? O git passou o seu commit para depois dos commits que vieram do repositório (apesar deles poderem ter ocorrido antes) e assim manteve a árvore organizada e fácil de entender.
Tem gente que fala que assim você perde a real história dos commits, mas eu discordo. Para casos em que a história é relevante eu uso o pull normal para deixar registrado o que aconteceu (por exemplo, estou criando uma aplicação a partir de uma outra open source e a original foi atualizada, aí sim eu faço um pull para mostrar que são commits de equipes diferentes que andaram em paralelo), mas para os casos de commits dentro da mesma equipe trabalhando numa mesma tarefa, acho que vale mais a árvore se manter legível.
Merge com a opção squash
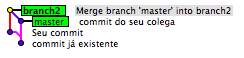
Geralmente eu uso branchs para separar as histórias do projeto que estão sendo criadas, sendo assim, imagine a seguinte situação:
Você criou um branch a partir do master para fazer sua história. Nesse seu branch você fez 23 commits, que foram totalmente úteis para você se organizar, integrar mais facilmente, etc.
Então você terminou sua história e vai fazer o merge para mandar sua nova funcionalidade para o remoto, então você faz:
git checkout master
git pull origin master (imaginando que você não commitou nada no seu master, senão o mais correto é git pull --rebase)
git checkout seu_branch
git rebase master
git checkout master
git merge seu_branch
git push origin master
Com isso você atualizou seu master, integrou as atualizações do master com o seu branch, fez o merge do seu branch no master e aí sim enviou os seus 23 commits.
Até aí você fez tudo perfeitamente, mas existe uma outra ferramenta que pode te ajudar a se organizar, a opção –squash do merge.
Quando você faz o merge com –squash (git merge seu_branch –squash) o git leva as atualizações pro seu branch mas como se elas não tivessem sido commitadas. Aí você faz um único commit e manda só ele para o master.
Para quem está olhando o master, faz mais sentido ver um commit por funcionalidade, enquanto para quem está desenvolvendo a funcionalidade os 23 commits são úteis. Então agindo assim a gente ajuda todo mundo. Ficaria assim:
git checkout master
git pull origin master
git checkout seu_branch
git rebase master
git checkout master
git merge seu_branch --squash
git add .
git commit -am "Minha funcionalidade"
git push origin master
Opção stash do git merge
Uma outra ferramenta útil é o stash. Imagine que você vai fazer uma atualização pequena no seu projeto e resolveu fazer no branch master mesmo (para aplicações que dividem o projeto em dois remotos – produção e desenvolvimento – eu acho isso totalmente normal). Só que enquanto você está fazendo você percebe que será uma atualização grande e seria mais interessante fazer isso num branch a parte (ou alguém te chamou para fazer outra coisa e você não vai poder continuar aquilo no momento). Então você está com algumas modificações sem commitar mas você não vai poder commitar no master, porque não está concluído, etc.
Para isso você pode usar o stash, você faria assim:
git stash (o git guarda todas as suas modificações em um lugar a parte e seu branch atual passa a ficar como se ninguém tivesse mexido - você pode usar git status para confirmar)
git checkout -b seu_branch_novo
git stash apply (suas modificações voltam a aparecer, pode confirmar com git status)
git commit -am "Primeiro commit da minha funcionalidade"
git stash clear (apaga tudo o que estava no stash)
git checkout master
Com isso você fez como se tivesse começado desde o início em um branch novo.
Você consegue também criar e gerenciar mais de um stash, mas geralmente um só satisfaz minha necessidade.
Opção track do git branch
Vamos a mais uma situação. Seu colega começou uma funcionalidade em um branch a parte e depois de alguns dias pediu para você ajudar ele nessa tarefa.
Você tem que trabalhar nesse mesmo branch dele, então você decide criar o branch dele localmente. Você faz:
git branch branch_dele
git checkout branch_dele (você poderia ter usado git checkout -b branch_dele e fazer tudo de uma vez)
git pull origin branch_dele
Caso deseja ver o artigo completo, acesse ele aqui.
Até a próxima 😉